{{title}}
{{#subtitle}}{{{subtitle}}}
{{/subtitle}}カテゴリ {{#document_type}} {{.}} {{/document_type}}
{{#desc}}{{desc}}
{{/desc}}カテゴリ {{solution_label}}
先端技術コラム The Pionnering Edge
タグ コラム
カテゴリ 予測AI 業種・業界共通 業務効率化・業務自動化・業務プロセス改善 コスト削減・コスト最適化・経費削減 データドリブン経営 AI・データ利活用 デジタルソリューション&コンサルティング 生成AI 予測AI

AI の歴史についての連載2回目。前回 はAIの勃興期の第一次AIブームから第二次AIブームの主要な出来事について、NSSOL の取り組みも一部交えつつ、概観した。
前回の冒頭で、以下のように書いた。
AIは、これまで3度のブームと2度の「冬の時代」を経験してきた。そして現在は、第4次AIブームの最中にある。 現在は第3次AIブームから冬の時代を経ることなく、直接第4次AIブームに移行した稀有な状況である。 今回のAI ブームは本物なのか?
答えはYes でもあり、No でもあると思う。
現在の AI が本当に使えるものである、という意味では、Yes である。 しかし、今回のAI ブームは一過性のもの(ブーム)ではなく、これからはAIを前提とした社会になる、という意味では No である。
では現在のAI は、これまでと何が違うのか、どんな課題があるのか。
AIの歴史と教訓を振り返りながら、考えてみたい。
「ブーム」と書いたが、今のAIはブームではなく、AIを使うのは当たり前の世の中になる。AIを前提とするのが、いわばニューノーマルである。(上記の主張は、この現行の草稿を書いていた2025年9月時点ではまだ議論の余地があったが、2026年3月現在では、AI浸透が進み、もはや自明かもしれない。)
今回は、第3次AIブームを振り返り、現在の第4次AIブームに通じる教訓と指針を示してみたい。
第一次AIブーム (1950年~1960年代)
第二次AIブーム (1970年代後半~1990年前半)
第三次AIブーム (2010年代中盤~2020年代中盤)
第四次AIブーム (2022年~現在)
長い冬の時代を終え、2010年代中盤から、第3次AIブームが始まる。 契機となったのは、ディープラーニングの登場である。
2012年、画像認識コンテストで、ジェフリー・ヒントン率いるトロント大学のチームが二位のチームに大差をつけて優勝した。 従来手法を用いた2位のチームのエラー率は、約26%。対して、優勝したトロント大学のチームのエラー率は 約 15%。
まさに圧勝である。 このときトロント大学のチームで使われた技術こそが、ディープラーニングであり、第3次AIブームはここから始まったと言える。
2016年には、DeepMindが開発したAlphaGoが、当時の囲碁世界チャンピオンの李世乭九段を破る。 AIの可能性を広く世界に示した瞬間であった。
ディープラーニングは、多層ニューラルネットワークである。 第1回で見たように、多層ニューラルネットワークの概念自体は古く、1960年代から存在していたが、長い間「理論的には面白いが実用にはならない」技術として扱われてきた。
ブレークスルーを生み出した要因は、アルゴリズムの進化、コンピュータリソースの充実、データセットの大規模化の3つである。
ディープラーニングは3つ以上の層を持つ多層のニューラルネットであり、教師あり機械学習モデルに属する。
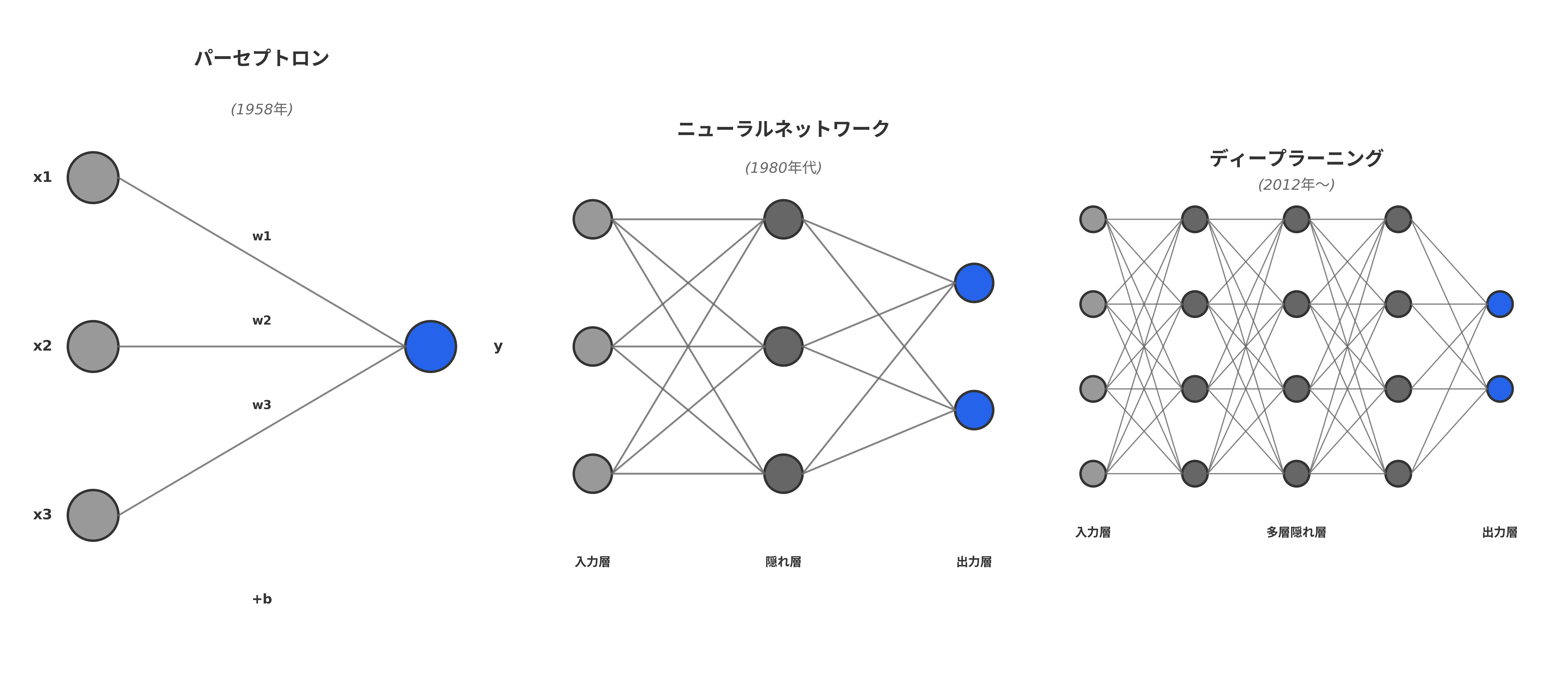
教師あり機械学習では、正解データ(ラベル付きデータとかアノテーション済みデータなどという)を与え、モデルが正解を再現できるように学習する。
例えば、画像に含まれる物体(ネコ、犬、など)を認識する問題であれば、画像本体と画像に含まれる物体のラベル(ネコ、犬などが記載された答えのデータ)のセットをデータとして与え、
画像に含まれる物体をモデルが正しく認識できるように学習する。
多層のニューラルネットの長年の課題は、端的に言うと、学習がうまく行かないことであった。
学習がうまく行かないのは、主に、勾配消失問題と過学習の二つの問題がある。
ディープラーニングモデルにおける学習では、教師データを再現するように、各層の重み(Weight)とバイアス(bias) のパラメータを調整する。
層が深くなればなるほど、調整すべき重みやバイアスの数が多くなる。
以下に学習のイメージを説明する。
ディープラーニングの学習では、教師データとディープラーニングモデルの出力の誤差が少なくなるように、各層の重みの値を変え、最適な重みを探していく。
重みは、誤差が少なくなる方向に変える。この誤差が少なくなる方向を「勾配」と呼ぶ。
※数学的にはベクトル微分をすることにあたる
層が深く大きなネットワークなると、この勾配が、少しづつ小さくなり、最後はほぼゼロになってしまう現象が発生する。これが勾配消失問題である。
勾配消失問題が発生すると、勾配がゼロになるので、教師データをよく再現する重みを見つける前に、学習が終わってしまう。
未学習(Under fitting)と言われる状態である。
ちょっと話が複雑になったので、仕事にたとえてみる。
大勢の人がいる複数の部署と連携しながら複雑な仕事を成し遂げる状況を考えてみよう。
最初の部署が熱意をもって仕事をお願いしていたのに、複数の部署を経由する間に、情報や熱意が失われ、やがて仕事が止まってしまう。
このような状況が勾配消失問題である。
もう一つの過学習(over fitting)の問題は、逆にモデルが学習データに適合しすぎて、未知のデータに対する性能が低下する問題である。
これは、人間に例えれば、問題集に載っている問題と答えを丸暗記はして試験に臨んだが、問題集に載っていない問題には答えられないような状況である。
学習がうまく行かない問題を解決するために、様々な工夫が行われた。
詳細は割愛するが、例えば、
こうした工夫の結果、層が深くパラメータが大きなネットワークであるディープラーニングでも適切に学習できるようになった。
この間、CPUの高速化に加え、クラウドコンピューティングが発展し、大規模な計算機リソースの調達が容易になった。
そして、GPUが登場。GPUは、並列計算による学習時間の劇的短縮が実現した。
インターネットの発達やクラウドコンピューティングの発展により、ディープラーニングに必要なラベル付きのデータも大量に手に入るようになった。
先に述べたImageNet(120万枚、1000クラス)のデータを使って学習している。
どのようにして学習データの大規模化が進んだのか。
まず、2000年代後半からインターネット上に大量に画像がたまるようになり、学習データになる画像の量がそれまでに比べ圧倒的に増えた。
しかし、単に画像があるだけでは、機械学習には使えない。
学習するには、この画像は「猫」、この画像は「車」のようなラベリングが必要だ。
ここで、クラウドソーシングで多数の人が少しづつラベル付け作業をする仕組みがでてきた。
ネット上の大量画像と大人数でのラベリングが結びついて、学習に適した大規模なデータセットが利用可能になったのである。
以上、ディープラーニングにブレークスルーをもたらした3つの要素を見てきた。
この3要素は相互に関連している。
つまり、大規模データがあってもコンピューティングリソースがなければ学習できず、コンピューティングリソースがあってもアルゴリズムが未熟では性能が出ない。
これまで連綿と続いてきた技術的な改善の蓄積、コンピューターリソースの拡充、データ整備の3つが2012年に実現したことで、ディープラーニングのブームが生まれたのである。
第3次AIブームにおけるもう一つの重要な技術革新は、Auto ML(Automated Machine Learning)の登場だと筆者は考える。
Auto ML は高精度な機械学習モデルを自動的に作成することができるプラットフォームである。Auto ML の製品を使えば、様々な機械学習のアルゴリズムから最適なものをほぼ全自動で作成することができる。
第3次AIブームが加速する中、新たに顕在化した課題は、データサイエンティストの不足だ。
機械学習モデルの構築には高度な専門知識が必要で、従来、専門のデータサイエンティストが担っていた。
そのデータサイエンティストには、3つのスキルが必要である。
統計・機械学習アルゴリズムなどいわゆるデータサイエンスのスキル、データ基盤を理解しデータを加工するデータエンジニアリングのスキル、
そして、業務を理解して業務課題にAIを適用するビジネスの力である。
しかし、このような3つのスキルを備えた人材を非常に希少である。
一般企業が確保するのは非常に困難ではないだろうか。
参考:データサイエンティスト協会 スキルチェックリスト ver 3. https://www.datascientist.or.jp/common/docs/PR_skillcheck_ver3.00.pdf
余談ながら、「データサイエンティストが21世紀で最もセクシーな職業だ」という聞いたことがある方も多いだろう。この言葉は、アナリティクスの権威トーマス・ダベンポート教授らが2012年にハーバードビジネスレビューに発表した論考(Data Scientist: The Sexiest Job of the 21st Century)が基になっているようだ。
参考: https://dhbr.diamond.jp/articles/-/1565
筆者も、当時、日本の企業人から「何がセクシーか」と不思議そうな顔でよく質問された。ここでの「セクシー」は、「かっこいい、流行りの」くらいの意味である。
(コリンズ英語辞典第13版によると、sexyの意味の3番目に、interesting, exciting, or trendy とある。実は筆者も留学中に戸惑ったのだが、アメリカ人はsexy という言葉を公の場でもけっこう気軽に良い意味で使うのである。)
少し脱線したが、データサイエンティスト不足の問題を解決すると期待されるのが、Auto ML である。
博士号を持つような専門的な教育を受け、かつ、ビジネスも分かるようなデータサイエンティストを確保するのは難しいので、
Auto MLを使いながら、一般の社員が機械学習モデルを作って、自らのビジネス課題を解決することを目指すのである。
専門のデータサイエンティストではないが、基礎的な分析力を備えて現場の課題をAIで解決する人材を、「市民データサイエンティスト」と呼ぶ。
Auto ML で武装した市民データサイエンティストを育成することによって、企業のAI活用を民主化する動きが2016年以降、国内でも進展した。
上で述べた「データサイエンティストが21世紀で最もセクシーな職業だ」を書いたトーマス・ダベンポート教授らも、2022年には、Auto ML を用いた、市民データサイエンティストによる民主化の可能性について言及している。
参考:「データサイエンティストはまだ21世紀で最もセクシーな職業か?」https://dhbr.diamond.jp/articles/-/8782
私自身、Auto ML を用いたAI 民主化に2016年から取り組んできた。その経験も踏まえて、述べてみたい。
NSSOL の取組に入る前に、少し補足しておく。 Auto ML で様々な機械学習のアルゴリズムから最適なものをほぼ全自動で作成することができる、と冒頭書いた。
複数のアルゴリズムを試さなくても、最初からディープラーニングを使えば良いではないか、と思われるかもしれない。 しかし、ディープラーニングは万能ではない。 あらゆる問題にとって最適な手法というのは存在しない。(これをノーフリーランチ定理という)
ディープラーニングは特に1つのデータに情報量が多く、かつ、データ量が多いときに非常に有効な手法である。 例えば、画像は、ピクセルの数だけのデジタル情報が含まれているため、一つのデータに含まれる情報量が多い。データに含まれる情報を多次元の入力として受け取って、学習を進める。 データが大量にあれば、大きなネットワーク(層が深く、調整すべき重みの数が多い)でも学習がうまくできる。
しかし、学習するのに必要な情報量が少なく、利用できるデータ量も少ない場合は、もっと単純なモデルの方が適している。
ここから、筆者も深くかかわったNSSOL の取組について、振り返りたい。 NSSOLは、2016年に DataRobot という、Auto ML 製品の代理店を始めた。それ以来、AIの活用やAI 民主化の支援に取り組んできた。 DataRobot は、Auto ML のパイオニア的製品である。当時のインパクトはすさまじかった。 データをドラッグ&ドロップして、数クリックするだけで、定番の機械学習モデルから最先端の機械学習モデルまで、数多くのモデルを同時に作ることができる。 そして、出来上がったモデルを評価して、一番良いモデルを選択し、予測サーバーにデプロイすれば、API 経由ですぐに他のシステムから呼び出して使うことができる。 さらに、モデルの精度の監視なども自動的に行うこと(いわゆるMLOps)ができる。
NSSOL が取り組んでいる AI民主化とは、AIを企業の競争力に変えるための戦略的アプローチである。 その核心は「AI内製化」と「AI実機化」という二つの柱にある。 (※ここでは、生成AI以前の2023年頃までの機械学習を中心としたAIについて述べる)
AI内製化は、業務担当者自身、つまり市民データサイエンティストがAIを構築する体制を指す。 データサイエンティスト不足という制約を乗り越え、現場のニーズに即応できる機動力を獲得する。 スピードと実用性が両立し、「現場で本当に使えるAI」が生まれる土壌となる。
AI実機化は、AIを業務システムに組込み、より多くの社員がその成果を享受できる状態にすること。 業務システムを通じてAIの価値を実感する。それは全社的なAIリテラシーの向上を促し、技術に対する適切な期待値を組織全体に根付かせる。
NSSOL は、AIのCoE 組織支援、テーマ創出、テーマレビュー、モデルチューニング・評価、人材育成、システム連携・構築など、AI民主化のための多様な支援を提供している。
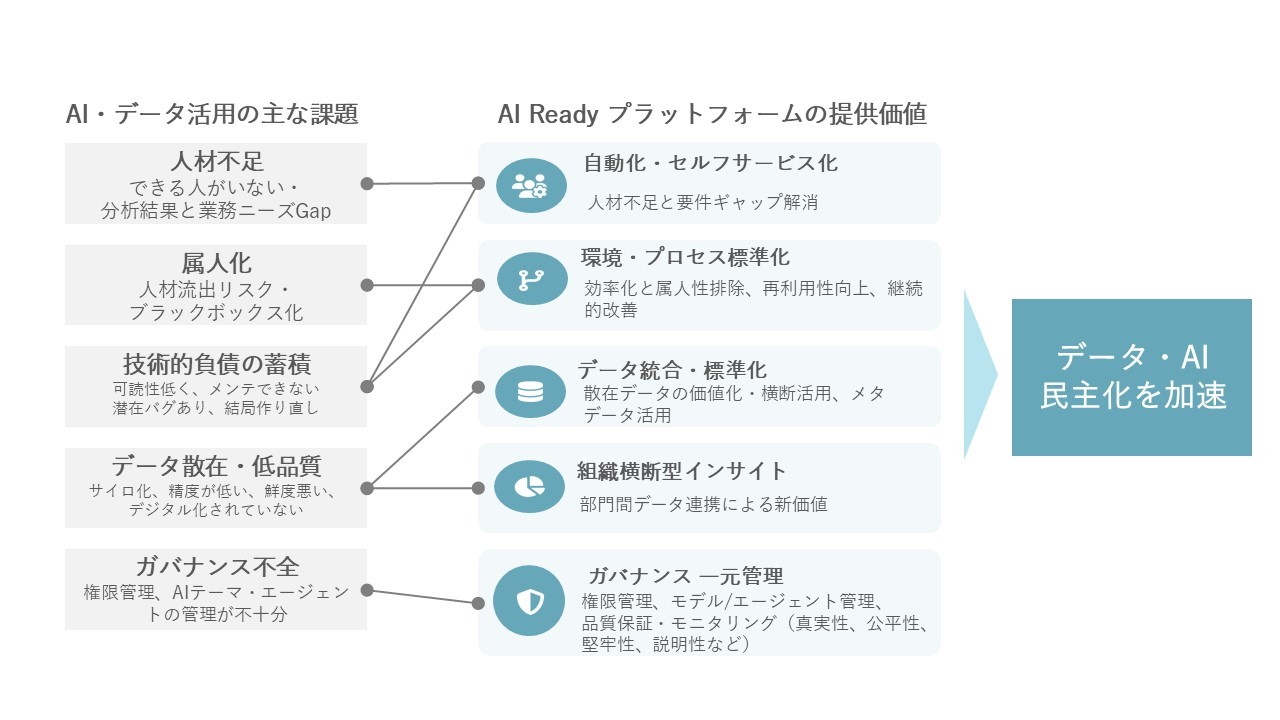
実際、この方向性で着実に成果を出す企業が存在する。 しかし、乗り越えるべき壁に直面している企業が多いのも事実だ。
筆者がAI民主化を支援する中で経験した壁を、少し赤裸々に述べてみる。
データサイエンティストはソフトウェアエンジではないので、書いたコードは、可読性や拡張性が低いことも多い。これは、ある意味技術的な負債であり、AI のアセット化を妨げる原因になっている。 実際、筆者も「俺がいれば、Auto ML などいらない」と言い放った上で、半年後に転職し、引継ぎも十分でなく、プロジェクトが止まってしまった、というケースに遭遇したことがある。 ここまでひどいケースは稀だが、専門的なデータサイエンティストの流動性の高さ、アセット化不足によって、組織的にAI の活用が停滞するのは、よく見られる事象である。
ディープラーニングの登場によって一気に脚光を浴びたAI。ディープラーニングは、生成AI の基盤技術として、さらに重要性を増していくことになる。 そして、Auto ML の登場に、データサイエンティストの仕事は、ビジネス課題を読み解きAI で解決する仕事に移行している。 日本のデータサイエンティスト協会のスキルチェックリストも、2025年度版は、ビジネス力を価値創造スキルとして再定義し、融合スキル群等を加えた形で大幅に改訂された。 (https://www.datascientist.or.jp/news/n-pressrelease/post-4959/)
前項まで、生成AI 前夜における AI民主化の5つの壁を見てきた。 この壁を超えるには、中長期的な視点で、AI 戦略を立案し、コミットメントをもって実行することが必要である。
質の良いデータを使って、精度が良く信頼性の高い予測モデルができれば、現場の活用が促進される。これをAI プラットフォームで効率化する。 Auto ML AIプラットフォームを前提とした、AI 民主化の活動の中で専門のデータサイエンティストと市民データサイエンティストが協力することで、新たなユーザーが育ち、新しいAIユースケースを生み出していく。 AI ユースケースが生まれれば、データが蓄積され、さらにAIの現場適用が進んでいく。 筆者はこれをAI・データ活用のフライホイール効果(弾み車のような好循環)と呼んでいる。 もちろん、全ての前提はAI戦略と経営のコミットメントである。
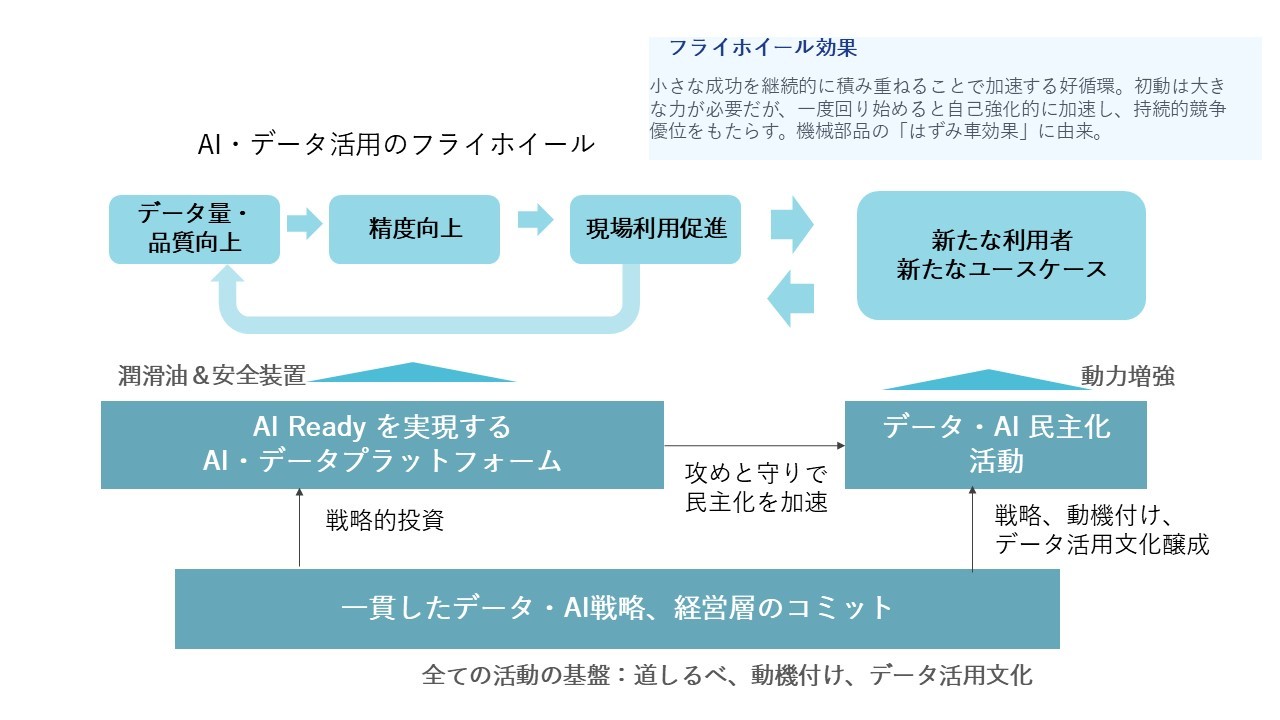
現在の生成AI 時代はどうだろうか? 生成AI は事前に学習済みなので、データがなくてもすぐに使える。動作原理は難しいが、基本的な使い方だけなら誰でも出来る。人材育成ほとんど不要である。 経営層も効果を体感しており、非常に関心が高く、コミットメントもこれまでの機械学習による個別のAIよりも、はるかに得やすい。 AIエージェントはシステム開発のコストを大きく下げつつ、業務を大きく自動化・効率化する可能性を秘めている。つまり、ラストワンマイルの問題を解消するチャンスである。
AIプラットフォームは、従来の機械学習のAutoML に加え、生成AIやAIエージェントに対応する形で拡張が進んでいる。
生成AI 時代の今こそ、データ・AI のフライホイールを回す条件が満たされているのである。 この好機を逃してはならない。中長期的なAI戦略の下で、全力でAIを推進するべき時だ。
次回は、生成AI登場以降の第4次AIブーム(ブームではなくニューノーマルであるが)について、詳細に考察し、あわせて、将来を展望してみたい。
本稿の引用は以下の記事をもとにしています。
出典:Harvard Business Review “Is Data Scientist Still the Sexiest Job of the 21st Century?”
https://hbr.org/2022/07/is-data-scientist-still-the-sexiest-job-of-the-21st-century