{{title}}
{{#subtitle}}{{{subtitle}}}
{{/subtitle}}カテゴリ {{#document_type}} {{.}} {{/document_type}}
{{#desc}}{{desc}}
{{/desc}}カテゴリ {{solution_label}}
先端技術コラム The Pioneering Edge
タグ コラム
カテゴリ 予測AI 業種・業界共通 業務効率化・業務自動化・業務プロセス改善 コスト削減・コスト最適化・経費削減 データドリブン経営 AI・データ利活用 デジタルソリューション&コンサルティング 生成AI 予測AI

AIは、これまで3度のブームと2度の「冬の時代」を経験してきた。そして現在は、第4次AIブームの最中にある。現在は第3次AIブームから冬の時代を経ることなく、直接第4次AIブームに移行した稀有な状況である。
今回のAI ブームは本物なのか?
答えはYes でもあり、No でもあると思う。
現在の AI が本当に使えるものである、という意味では、Yes である。しかし、今回のAI ブームは一過性のもの(ブーム)ではなく、これからはAIを前提とした社会になる、という意味では No である。
では現在のAI は、これまでと何が違うのか、どんな課題があるのか。AIの歴史と教訓を振り返りながら、考えてみたい。
第一次AIブーム (1950年~1960年代)
第二次AIブーム (1970年代後半~1990年前半)
第三次AIブーム (2010年代中盤~2020年代中盤)
第四次AIブーム (2022年~現在)
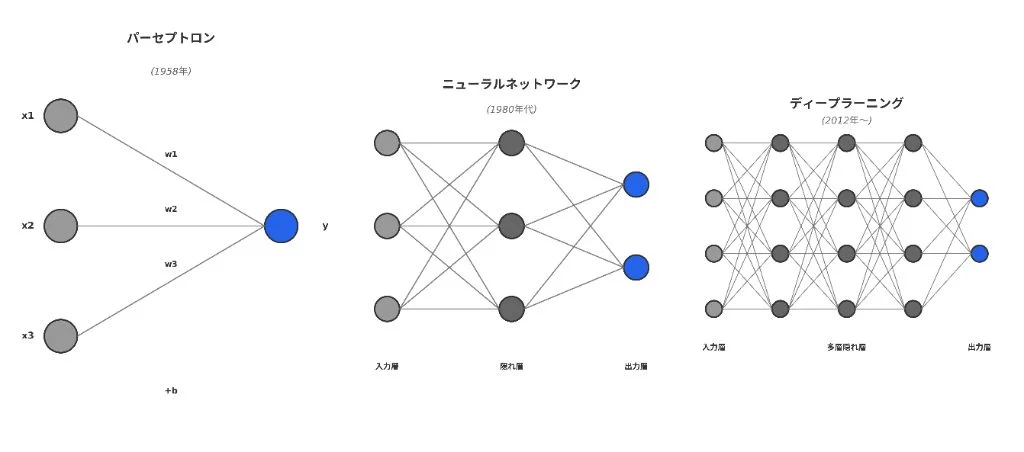
AI の歴史は長く、コンピュータ黎明期の1950年代には既に研究が始まっている。 第一次AI ブームは、1950年~1969年。AIという用語が始めて使われた1956年のダートマス会議、1958年のパーセプトロンの開発の後の1960年前後がブームの中心だろう。
筆者は実際にこの時代を体験していないので、当時の雰囲気はわからない。しかし、今から60年も前のコンピュータ黎明期に、既に AI の重要な概念がほぼ全て登場しているのは驚くべきことだ。
知能とは何かを問うチューリングテスト、人間の脳を模したアルゴリズムであるパーセプトロン、コンピュータが実問題を扱う際の難しさを明示するフレーム問題。哲学的、科学的、工学的にも本質的な問題に正面から取り組んでいる。「ブーム」という言葉では軽すぎて、先達に対してなんだか申し訳ない気持ちになる。
ただし、この時期は、簡単化したゲームのような問題(いわゆるトイプログラム)は解くことが出来たが、現実的に有用な問題は解くことが出来ず、ビジネスの観点でいうと目ぼしい成果はなかった。そして、AIは最初の冬の時代に入る。 この時期の主要な成果と課題を概観してみる。
チューリングテストでは、質問者が文字のみの質疑応答を通してコンピュータと対話し、人間とコンピューターの区別がつかなければ、そのコンピュータはテストに合格したとみなす。チューリングテストは、AIの研究だけでなく、人間とは何か、知能とは何か、という哲学的に重要な命題としても後々まで大きな影響を与えている。例えば、1980年の 哲学者のサールは、「中国語の部屋」の例えを用いてチューニングテストを批判している。チューニングテストに形式的に合格したからといって、コンピュータが意味を理解しているとは言えず、知能があるとは言えない、という反論である。
第一次AIブームの後半から冬の時代にかけて、入力層と出力層からなる単純パーセプトロンの発展系として、入力層、中間層(隠れ層)、出力層からなるニューラルネットによって、単純パーセプトロンの表現力の限界を突破する試みがなされていた。 1967年には、甘利俊一氏が確率的勾配降下法を提案し、多層のニューラルネットの学習方法に改善がなされた。5層のニューラルネット(5層のパーセプトロン)の学習が行われた。ニューラルネットの層を増やせば、表現力が増し、モデルの精度も上がると理論的には分かってきたため、多くの研究者や実務家が取り組んだ。
NSSOL (前身の新日鉄)では、この時期から、エキスパートシステムを中心としたAI の研究開発に非常に力を入れ、多くの実機化の取り組みもなされた。
当時は経営合理化、多角化の時代であり、製鉄操業の効率化、熟練技術者の技能伝承や属人化の回避がAI活用の大きなモチベーションであった。
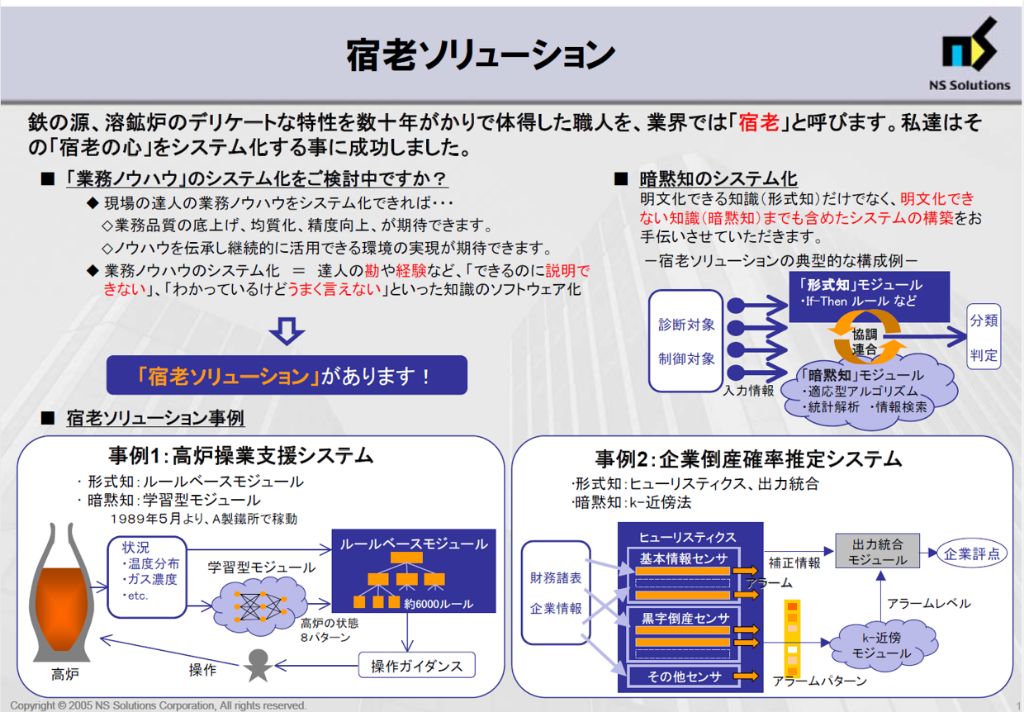
NSSOL の取り組みでも特徴的な「宿老モデル」について紹介する。
宿老とは、製鉄所の中核設備である高炉(溶鉱炉)の制御を行う熟練の職人のことである。高炉は製鉄所の最上流のプラントで、高炉内部は高温高圧で直接観測することが出来ない。宿老の経験と勘に基づく判断は、製鉄プロセスの品質と効率を左右する重要な要素であった。
宿老モデルは、宿老が持つ暗黙知を形式知として体系化し、エキスパートシステムとして実装したものである。形式知化できない部分は、ニューラルネットなどの機械学習の手法で、宿老が行ったオペレーションを手本として学習を行う(技術的には、特定の環境条件下での宿老のオペレーションを教師データとして蓄積し、ニューラルネットに学習させる)。 暗黙知のうち形式知化としてルール化されたものが80%、残り20% の暗黙知を機械学習でデータから学習するような実装イメージである。宿老モデルは、操業の全自動化には使われなかったが、一定の有用性があり、高炉操作の操作ガイダンスとして利用された。
NSSOL では、一般企業向けにも「宿老モデル」を応用したシステムの構築を行った。 例えば、企業の与信管理のエキスパートを「宿老」と見立て、倒産確率を推定する事例がある。 「こういう財務諸表の動きの会社は黒字倒産しやすい」など与信のエキスパートが持つヒューリスティクスからアラートを作成し、複数のアラートを総合して、機械学習も使いながら、意思決定を行うシステムである。
| 回 | 時期 | 内容(予定) |
| 第1回 | 10月 | AIの歴史と展望 ~AIの歴史から学ぶべきこと、これから私たちがすべきこと~ |
| 第1回(その2) | NEW! | AIの歴史と展望 ~AIの歴史から学ぶべきこと、これから私たちがすべきこと~(第三次AIブームからのつづき) |
| 第2回 | 11月 | AI エージェントの実相 ~現状の課題と対策、取るべき戦略~ |
| 第3回 | 12月 | AIの実運用とガバナンス |
| 第4回 | 12月 | 先端技術対談 業界のThought Leader との対談(仮) |
| 第5回 | 1月 | 2026年の技術展望 |
| 第6回 | 3月 | 先端技術トピック・要素技術・ノウハウ集(仮) ~小粒でもエッジが効いた技術達~ |